
Czym Jest Ciągła Integracja (Continuous Integration – CI)?
19 maja 2021

Ciągła integracja (CI – ang. Continuous Integration) coraz częściej pojawia się w kontekście tworzenia oprogramowania i wydaje się stosunkowo nowym podejściem. Termin ten jednak sięga początków lat 90-tych, kiedy to został użyty przez Grady Boocha (jednego z twórców języka UML) w książce pt. “Object Oriented Design: With Applications”. CI dalszy swój rozwój zawdzięcza upowszechnieniu się zwinnych metodyk tworzenia oprogramowania (Agile), w którym pełni jedną z kluczowych ról.
Ten artykuł podejmuje próbę odpowiedzi na pytanie: “Czym jest ciągła integracja i jak wpływa na jakość tworzonych aplikacji”.
Czym jest CI
Ciągła integracja to odpowiednie podejście do tworzenia oprogramowania, w której członkowie zespołu programistycznego często integrują wyniki swoich prac w postaci kodu źródłowego budowanej aplikacji. Zazwyczaj każdy z członków zespołu programistów integruje swoje zmiany w kodzie źródłowym aplikacji z wynikami prac swoich kolegów z zespołu przynajmniej raz dziennie. Każda taka integracja jest weryfikowana przez proces automatycznej budowy aplikacji oraz automatyczne testy w celu jak najszybszego wykrywania błędów integracji. Uważa się, że takie podejście prowadzi do znacznego ograniczenia problemów z integracją oraz umożliwia zespołom programistów na szybsze tworzenie spójnego oprogramowania i ułatwia zarządzanie projektami.
Narzędzia CI
Idea ciągłej integracji opiera się na wykorzystaniu narzędzi, które wspierają ten proces.
Jednym z tych narzędzi jest system zarządzania kodem źródłowym (SCM – source control management) znany również pod innymi nazwami takimi jak: system zarządzaniem konfiguracją, systemami kontroli wersji, repozytoria kodu. Oprogramowanie to służy do śledzenia zmian głównie w kodzie źródłowym oraz wspiera zespoły programistów w łączeniu zmian dokonanych w plikach przez wiele osób w różnym czasie. Obecnie dostępnych jest bardzo wiele różnych tego typu systemów. Najbardziej popularne to:
- GIT/GITHUB
- BITBUCKET
Kolejnym narzędziami związane z CI to systemy wspomagające budowanie, testowanie i wdrażanie, ułatwiając ciągłą integrację i ciągłe dostarczanie. Tak jak w przypadku poprzednich narzędzi również i tutaj dostępnych jest bardzo wiele rozwiązań. Najbardziej popularne to:
- Jenkins
- TeamCity
- Bamboo
- Buddy
- GitLab CI
- CircleCI
- TravisCI
Jak tworzyć kod z wykorzystaniem ciągłej integracji
Najłatwiejszym sposobem wyjaśnienia, czym jest CI i jak działa, jest pokazanie szybkiego przykładu. Załóżmy, że należy wykonać zmianę w kodzie źródłowym oprogramowania w celu dodania do niego nowej funkcjonalności.
Pracę nad kodem źródłowym oprogramowania rozpoczyna się od skopiowania repozytorium kodu. Robi się to za pomocą systemu zarządzania kodem źródłowym, sprawdzając kopię roboczą z głównej gałęzi repozytorium.
System kontroli kodu źródłowego przechowuje cały kod źródłowy projektu w repozytorium. Obecny stan systemu jest zwykle określany jako „gałąź główna”. W dowolnym momencie programista może wykonać kontrolowaną kopię głównej gałęzi na swoim komputerze.
Mając lokalnie kopię roboczą można wykonać zadanie związane z modyfikacją kodu źródłowego oprogramowania. Będzie to polegało zarówno na zmianie kodu produkcyjnego, jak i na dodaniu lub zmianie testów automatycznych. CI zakłada wysoki stopień wykorzystania testów, które są zautomatyzowane. Do opracowania testów najczęściej wykorzystywane są różnego rodzaju popularne frameworki.
Po zakończeniu modyfikacji w kodzie źródłowym, wykonuje się zautomatyzowany proces kompilacji (build) na lokalnej stacji roboczej. Proces ten pobiera kod źródłowy z lokalnej kopii roboczej repozytorium kodu, kompiluje i łączy go z plikiem wykonywalnym i uruchamia testy automatyczne. Tylko wtedy, gdy wszystko kompilacja i testy automatyczne przebiegają bez błędów, ogólna kompilacja jest uważana za poprawną.
Po poprawnej kompilacji można zatwierdzić zmiany w repozytorium. Problem w tym, że inni członkowie zespołu programistów w tym samym czasie mogą i zwykle dokonują zmian w głównej gałęzi kodu źródłowego. Dlatego najpierw aktualizuje się kopię roboczą na lokalny repozytorium, wprowadzając zmiany i dokonując ponownej kompilacji. Jeśli zmiany dokonane przez innych członków zespoły będą kolidować z wprowadzonymi zmianami, będzie to objawiać się niepowodzeniem w kompilacji lub w testach. W tym przypadku należy naprawić błąd i powtórzyć kompilację.
Po poprawnej kompilacji odpowiednio zsynchronizowanej kopii roboczej można ostatecznie zatwierdzić zmiany w głównej gałęzi kodu, a następnie zaktualizować główne repozytorium kodu.
Po aktualizacji głównego repozytorium następuje ponowna budowa kodu, ale tym razem na serwerze integracyjnym. Dopiero, gdy ta kompilacja się powiedzie, można uznać, że zmiany kodzie źródłowym zostały wykonane poprawnie. Zawsze jest szansa, że coś zostało przeoczone na lokalnej stacji roboczej, a repozytorium główne nie zostało odpowiednio zaktualizowane. Dopiero wtedy, gdy wprowadzone zmiany do repozytorium głównego budują się poprawnie na serwerze integracyjnym, zmiany można uznać za zrealizowane. Ta kompilacja integracyjna może być wykonana ręcznie ale najczęściej realizowana jest z wykorzystaniem wspomnianych wyżej narzędzi CI do kompilacji, testów i wdrażania.
Jeśli dojdzie do konfliktu w zmianach dokonanych w kodzie źródłowym między dwoma programistami, zwykle konflikt jest on wychwytywany, gdy drugi programista, który zatwierdził, tworzy zaktualizowaną kopię roboczą. W przeciwnym razie kompilacja integracji powinna zakończyć się niepowodzeniem. Tak czy inaczej, błąd jest szybko wykrywany. W tym momencie najważniejszym zadaniem jest dokonanie odpowiedniej naprawy kodu i przywrócenie poprawnego działania kompilacji. W środowisku Continuous Integration nigdy nie należy mieć nieudanych kompilacji integracyjnych przez długi czas. Dobry zespół programistów powinien otrzymywać dziennie wiele poprawnych kompilacji. Złe kompilacje mogą zdarzać się bardzo rzadko i należy je niezwłocznie naprawić.
W efekcie końcowym otrzymujemy stabilne oprogramowanie, które działa poprawnie i zawiera znikomą ilość błędów. Zespół programistów rozwijają kod na wspólnym stabilnym repozytorium kodu, a częste integrację kodu zajmuje bardzo mało czasu. Mniej czasu poświęca się również na szukanie błędów, ponieważ CI pomaga w szybkim i skutecznym ich wykrywaniu.
Najlepsze praktyki
W tej sekcji wymienione zostały najlepsze praktyki dotyczące sposobu podejścia do realizacji ciągłej integracji i jej automatyzacji. Jak się wydaje wprowadzenie procesu automatyzacji budowania aplikacji jest sama w sobie najlepszą praktyką.
Ciągła integracja jako praktyka polegająca na częstym integrowaniu nowego lub zmienionego kodu z istniejącym repozytorium kodu powinna występować na tyle często, aby między zatwierdzeniem kodu w repozytorium głównym a kompilacją nie pozostało żadne okno czasowe, tak żeby wszystkie błędy mogły być wychwycone przez programistów i natychmiast poprawione. Normalną i pożądaną praktyką jest wyzwalanie tych kompilacji przez każde zatwierdzenie do repozytorium, a nie okresowo zaplanowaną kompilację.
Innym czynnikiem jest potrzeba systemu kontroli wersji, który obsługuje niepodzielne zatwierdzenia; tj. wszystkie zmiany programisty mogą być postrzegane jako pojedyncza operacja zatwierdzania zmiany.
Aby osiągnąć te cele, ciągła integracja opiera się na poniższych zasadach.
Repozytorium kodu
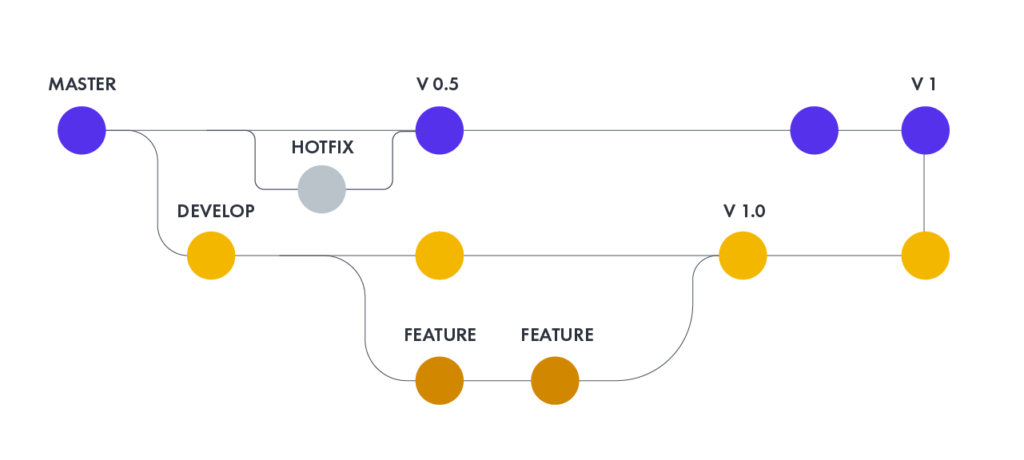
Ta praktyka zaleca stosowanie systemu kontroli wersji do zarządzania kodem źródłowym oprogramowania. Wszystkie pliki wymagane do zbudowania projektu należy umieścić w repozytorium. System powinien być możliwy do zbudowania w nowym środowisku systemowych i nie powinien wymagać dodatkowych plików, które nie znajdują się w repozytorium. Rozgałęzianie wersji kodu źródłowego powinno zostać zminimalizowane. Preferowane jest integrowanie zmian, a nie jednoczesne utrzymywanie wielu wersji oprogramowania. Gałąź główna powinna być miejscem dla działającej wersji oprogramowania. Rozsądne inne gałęzie to poprawki błędów wcześniejszych wersji produkcyjnych ewentualnie tymczasowy kod rozwojowy.
Zautomatyzowana kompilacja
Przekształcenie kodu źródłowego w działający system może być często skomplikowanym procesem obejmującym kompilację, przenoszenie plików, ładowanie schematów do baz danych i tak dalej. Jednak, podobnie jak większość zadań w tej części procesu tworzenia oprogramowania, można je zautomatyzować – a co za tym idzie, powinno zostać zautomatyzowane. Proszenie ludzi o wpisywanie dziwnych poleceń lub klikanie okien dialogowych wydaje się stratą czasu i wylęgarnią niepotrzebnych błędów.
Zautomatyzowane środowiska kompilacji są powszechną cechą systemów. Świat uniksowy rozwijał się przez dziesięciolecia, społeczność Java stworzyła Ant, społeczność .NET miała Nanta, a teraz ma MSBuild. Należ upewnić się, że można zbudować i uruchomić system za pomocą tych skryptów za pomocą jednego polecenia.
Częstym błędem jest nie uwzględnienie wszystkich elementów w automatycznej kompilacji. Kompilacja powinna obejmować pobranie schematu bazy danych z repozytorium i uruchomienie go w środowisku wykonawczym. Powinna zawsze istnieć zasada dzięki której jest możliwość pobrania kodu źródłowego z repozytorium i za pomocą jednego polecenia uruchomienie systemu na lokalnym komputerze lub serwerze.
Pojedyncze polecenie powinno mieć możliwość zbudowania systemu. Wiele narzędzi do budowania, takich jak make, istnieje od wielu lat. Inne nowsze narzędzia są często używane w środowiskach ciągłej integracji. Automatyzacja kompilacji powinna obejmować automatyzację integracji, która często obejmuje wdrożenie w środowisku podobnym do produkcji. W wielu przypadkach skrypt budujący nie tylko kompiluje pliki binarne, ale także generuje dokumentację, strony internetowe, statystyki i wersje instalacyjne (np. Debian DEB, Red Hat RPM czy Windows MSI).
Większość programistów używa do tworzenia oprogramowania tzw. zintegrowanego środowiska programistycznego (IDE), które ma w sobie jakiś proces zarządzania kompilacją. Jednak ten proces zazwyczaj zastrzeżony jest dla środowiska IDE i wykorzystuje go do swojego działania. Programiści mogą używać IDE do programowania i indywidualnej kompilacji na własnych lokalnych stacjach roboczych. Jednak ważne jest, aby mieć kompilację główną, którą można używać na serwerze i uruchamiać z odpowiednio przygotowanych skryptów.
Samokontrola kompilacji
Tradycyjnie kompilacja oznacza kompilację, linkowanie i wszystkie dodatkowe rzeczy wymagane do uruchomienia programu. Program może działać, ale to nie znaczy, że działa właściwie. Współczesne języki z typowaniem statycznym mogą wyłapać wiele błędów, ale wiele błędów umyka tej kontroli.
Dobrym sposobem na szybsze i wydajniejsze wychwytywanie błędów jest włączenie testów automatycznych do procesu kompilacji. Oczywiście testowanie nie jest doskonałe, ale może wykryć wiele błędów – wystarczająco dużo, aby testy te były przydatne. W szczególności powstanie zwinnych metodyk rozwoju oprogramowania przyczyniło się do spopularyzowania autotestowania kodu, w wyniku czego wiele osób dostrzegło zalety tej techniki.
Do automatycznego testowania kodu potrzebny jest zestaw testów, które mogą sprawdzić dużą część kodu pod kątem błędów. Testy muszą być uruchamiane prostym poleceniem i sprawdzać się samoczynnie. Wynik uruchomienia zestawu testów powinien wskazywać, czy jakiekolwiek testy zakończyły się niepowodzeniem. Aby kompilacja działała samodzielnie, niepowodzenie testu powinno spowodować niepowodzenie kompilacji.
W ostatnich latach powstało wiele narzędzi i bibliotek ułatwiających tworzenie i wykonanie różnego rodzaju testów oprogramowania w tym testy jednostkowe, interfejsów użytkownika, statyczną analizę kodu, etc.
Oczywiście nie można liczyć na testy, które pozwolą wykryć wszystkie błędy. Jak często się mówi: testy nie dowodzą braku błędów. Niedoskonałe testy ale uruchamiane często, są znacznie lepsze niż doskonałe testy, które nigdy nie zostały napisane.
Codzienne zmiany w repozytorium
Ta zasada mówi, że każdego dnia wszyscy członkowie zespołu programistów zobowiązują się do umieszczania zmian w głównym repozytorium kodu.
Poprzez regularne zatwierdzanie każdy zatwierdzający może zmniejszyć liczbę sprzecznych zmian. Sprawdzanie tygodniowej pracy wiąże się z ryzykiem konfliktu z innymi zmianami dodanymi do repozytorium przez innych członków zespołu i może być bardzo trudne do rozwiązania. Wczesne, małe konflikty w obszarze systemu powodują, że członkowie zespołu komunikują wcześniej i częściej o wprowadzanych zmianach.
Zatwierdzanie wszystkich zmian co najmniej raz dziennie jest ogólnie uważane za część definicji ciągłej integracji. Ponadto generalnie zaleca się wykonanie nocnej kompilacji. Zakłada się, że typowa częstotliwość wprowadzania zmian do repozytorium będzie znacznie wyższa. Częste zatwierdzenia kodu w repozytorium zachęcają programistów do dzielenia swojej pracy na małe fragmenty po kilka godzin każdy. Pomaga to śledzić zmiany i zapewnia poczucie postępu w budowaniu systemu.
Kompilacja po zmianie w repozytorium
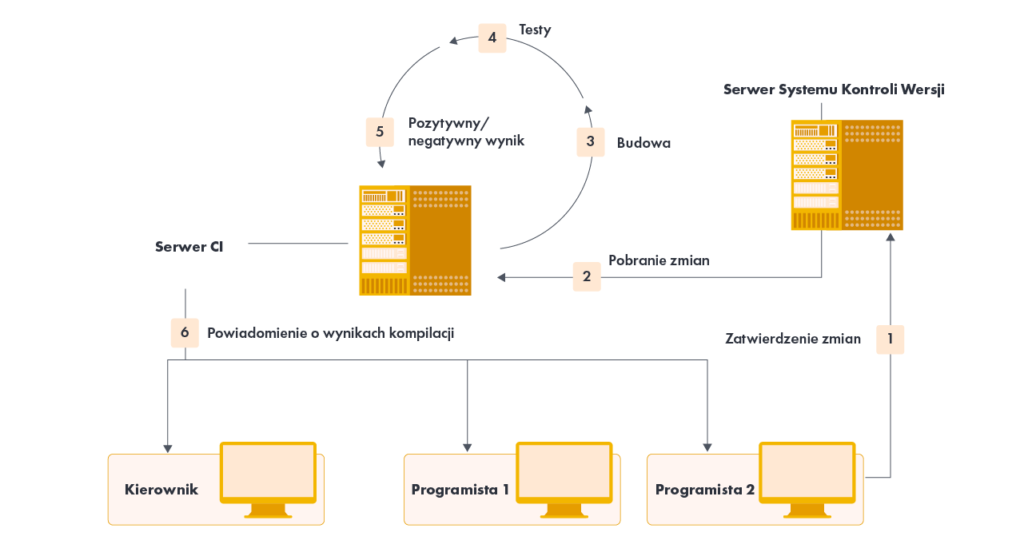
Po dokonaniu zmian w repozytorium kodu system powinien zbudować ostatnią wersję kodu, aby sprawdzić, czy jest on poprawnie zintegrowany. Powszechną praktyką jest używanie automatycznej ciągłej integracji, chociaż można to zrobić ręcznie. Automatyczna ciągła integracja wykorzystuje serwer ciągłej integracji lub demona do monitorowania systemu kontroli wersji pod kątem zmian, a następnie automatycznie uruchamia proces kompilacji.
Serwer ciągłej integracji działa jako monitor repozytorium. Za każdym razem, gdy zatwierdzanie w repozytorium kończy się, serwer automatycznie sprawdza źródła na maszynie integracyjnej, inicjuje kompilację i powiadamia osobę zatwierdzającą (oraz np. lidera zespołu) o wyniku kompilacji. Powiadomienia zostają przesłane zwykle e-mailem.
Wiele organizacji regularnie tworzy kompilacje zgodnie z harmonogramem, na przykład co noc. To oczywiście nie to samo, co ciągła kompilacja i nie jest wystarczające, aby nazywać to ciągłą integracją. Cały sens ciągłej integracji polega na jak najszybszym znajdowaniu problemów. Nocne kompilacje oznaczają, że błędy pozostają niewykryte przez cały dzień, zanim ktokolwiek je odkryje. Gdy już znajdują się w systemie tak długo, znalezienie i usunięcie ich zajmuje dużo więcej czasu.
Natychmiast napraw uszkodzone kompilacje
Kluczowym elementem realizacji ciągłej kompilacji jest to, że jeśli główna gałąź repozytorium kodu posiada problem i nie kompiluje się, należy ją natychmiast naprawić. Cały sens pracy z CI polega na tym, że zawsze oprogramowanie rozwijane jest w oparciu o stabilną podstawę.
Zwrot, który brzmi: „nikt nie ma ważniejszego zadania niż naprawianie kompilacji” nie oznacza tego, że wszystkie osoby w zespole muszą przerwać swoją pracę, aby naprawić główną gałąź repozytorium. Oznacza to jednak świadome nadanie priorytetu naprawie kompilacji jako pilne zadanie o wysokim priorytecie.
Często najszybszym sposobem naprawienia kompilacji jest przywrócenie ostatniego poprawnego zatwierdzenia z głównej gałęzi repozytorium, przywracając system do ostatniej dobrej wersji. O ile przyczyna awarii nie jest od razu oczywista, po prostu należy przywrócić główną gałąź repozytorium do stanu sprzed wystąpienia błędu i podjąć próby zdiagnozowania problemu na kopii lokalnej repozytorium na programistycznej stacji roboczej.
Kiedy zespoły wprowadzają CI, często jest to jedna z najtrudniejszych rzeczy do rozwiązania. Na wczesnym etapie zespół może mieć trudności z nabyciem regularnego nawyku pracy z wersją główną repozytorium, zwłaszcza jeśli pracuje na istniejącej bazie kodu. Niemniej cierpliwość i ciągła praca w tym zakresie w końcu daje efekty.
Utrzymuj szybką budowę
Celem CI jest zapewnienie szybkiej informacji zwrotnej. Nic tak nie zniechęca do wprowadzenia CI niż kompilacja, która zajmuje dużo czasu. Wytyczne w tym zakresie mówią, aby czas podstawowej kompilacji utrzymać na poziomie nie dłuższym niż 10 min.
Warto włożyć w to wysiłek, aby tak się stało, ponieważ każda minuta skrócenia czasu kompilacji to minuta zaoszczędzona dla każdego dewelopera za każdym razem, gdy się dodaje kod do głównej gałęzi repozytorium. Ponieważ CI wymaga częstych zatwierdzeń, w sumie zajmuje to dużo czasu.
Jak się wydaje, zwykle wąskim gardłem jest testowanie – szczególnie testy, które obejmują usługi zewnętrzne. Prawdopodobnie najważniejszym krokiem jest rozpoczęcie pracy nad konfiguracją tzw. potoku wdrożeniowego. Idea stojąca za potokiem wdrażania (zwanym również potokiem kompilacji lub kompilacją etapową) polega na tym, że w rzeczywistości wiele kompilacji jest wykonywanych po kolei. Zatwierdzenie do głównej głównej gałęzi repozytorium uruchamia pierwszą kompilację. Kompilacja ta, którą należy wykonać szybko zmniejszając równocześnie ilość wykonywanych testów w jej trakcie. Należy tutaj zrównoważyć potrzeby związane z wyszukiwaniem błędów i szybkości, tak aby pozytywna kompilacja była wystarczająco stabilna, aby inni członkowie zespółu mogli nad nią pracować w oparciu o aktualną wersję kodu źródłowego. Istnieją jednak dalsze, wolniejsze testy, które można zacząć wykonywać. Dodatkowe maszyny mogą uruchamiać dalsze procedury testowe w kompilacji, które trwają dłużej.
Prostym przykładem tego jest dwuetapowy potok kompilacji. Pierwszy etap polegałby na kompilacji i uruchomieniu testów, które są bardziej specyficznymi testami jednostkowymi np. z całkowicie pustą bazą danych. Takie testy mogą przebiegać bardzo szybko, zgodnie z wytycznymi dotyczącymi dziesięciu minut. Jednak żadne błędy, które obejmują interakcje na większą skalę, szczególnie te dotyczące prawdziwej bazy danych, nie zostaną znalezione. Kompilacja drugiego etapu uruchamia inny zestaw testów obejmujących bardziej kompleksowe zachowanie systemu. Uruchomienie tego pakietu może zająć nawet kilka godzin.
Jeśli ta dodatkowa kompilacja się nie powiedzie, może to nie mieć tej samej ważności typu „zatrzymaj wszystko”, ale zespół stara się naprawiać takie błędy tak szybko, jak to możliwe, przy jednoczesnym utrzymaniu działania wersji głównej gałęzi repozytorium.
Ten przykład przedstawia potok dwustopniowy, ale podstawową zasadę można rozszerzyć na dowolną liczbę kolejnych etapów. Kompilacje można również wykonywać równolegle. Można wprowadzić wszelkiego rodzaju dalsze testy automatyczne, w tym testy wydajności, do zwykłego procesu kompilacji.
Testy na klonie środowiska produkcyjnego
Celem testowania jest usunięcie, w kontrolowanych warunkach, wszelkich problemów, jakie system będzie miał podczas produkcji. Znaczną część tego stanowi środowisko, w którym będzie działał system produkcyjny. Jeśli testy przeprowadzane są w odmiennym środowisku, każda różnica powoduje ryzyko, że to, co dzieje się podczas testu, nie wydarzy się w środowisku produkcyjnym.
W rezultacie należy skonfigurować środowisko testowe tak, aby jak najdokładniej odzwierciedlać środowisko produkcyjne. Należy użyć tego samego oprogramowania bazy danych, z tymi samymi wersjami, tej samej wersji systemu operacyjnego. Umieścić należy wszystkie odpowiednie biblioteki, które są w środowisku produkcyjnym, w środowisku testowym, nawet jeśli system w rzeczywistości ich nie używa. Użyć należy tych samych adresów IP i portów, uruchamiając na tym samym sprzęcie.
W rzeczywistości istnieją ograniczenia. Pomimo tych ograniczeń celem nadal powinno być maksymalne powielanie środowiska produkcyjnego i zrozumienie ryzyka, które jest akceptowalne w przypadku każdej różnicy między testem a produkcją.
Do powyższych testów coraz częściej wykorzystywane są środowiska zwirtualizowane, aby ułatwić zestawianie i konfigurację środowisk testowych. Zwirtualizowane maszyny można zapisać wraz ze wszystkimi niezbędnymi elementami. Następnie stosunkowo łatwo jest zainstalować najnowszą kompilację i uruchomić testy. Ponadto pozwala to na uruchamianie wielu testów na jednym komputerze lub symulowanie wielu maszyn w sieci na jednym komputerze.
Dostęp do najnowszej wersji
Każda osoba zaangażowana w rozwój danego oprogramowania powinna mieć dostęp do najnowszej wersji tego oprogramowania i być w stanie go uruchomić: na potrzeby demonstracji, testów eksploracyjnych lub po prostu zobaczyć, co zmieniło się w danym dniu lub tygodniu. W tym celu należy umieścić odpowiednią informację o najnowszych wersjach oprogramowania w ogólnie dostępnym miejscu na przykład na odpowiednim serwerze.
Każdy może zobaczyć, co się dzieje
Ciągła integracja polega na komunikacji, dlatego należy zapewnić łatwy dostęp członków zespołu do informacji o stanie systemu i wprowadzonych w nim zmianach.
Jedną z najważniejszych rzeczy do przekazania jest stan wersji głównej. Wiele narzędzi CI posiada wbudowaną witryną internetową, która pokazuje, czy trwa kompilacja i jaki był stan ostatniej wersji gałęzi głównej repozytorium kodu. Wiele zespołów chce, aby było to jeszcze bardziej widoczne, dołączając graficzną reprezentację procesu kompilacji – popularne są światła, które świecą na zielono, gdy kompilacja działa, lub na czerwono, jeśli się nie powiedzie. Szczególnie częstym rozwiązaniem są czerwone i zielone kontrolki – nie tylko wskazują one stan kompilacji, ale także czas jej trwania. Odpowiednie informacje graficzne wskazują, że kompilacja trwała zbyt długa.
Oczywiście strony internetowe serwerów CI mogą zawierać więcej informacji, wskazując nie tylko tego, kto buduje, ale także jakie zmiany wprowadził. Serwery CI często zawierają również historię zmian, umożliwiając członkom zespołu dobre zorientowanie się w ostatnich działaniach w projekcie i dając poczucie, że budowany system rozwija się w odpowiednim tempie.
Kolejną zaletą korzystania z witryny internetowej CI jest to, że osoby, które pracują w innych lokalizacjach niż zespół główny lub zespół jest rozproszony, wtedy mogą oni uzyskać ciągłe informacje o statusie projektu. Serwery CI również często posiadają możliwość agregowania informacji z wielu projektów – zapewniając prosty i automatyczny status różnych projektów.
Zautomatyzowane wdrażanie
Aby przeprowadzić ciągłą integrację, potrzebnych jest wielu środowisk do przeprowadzania testów. Ponieważ przenoszenie budowanych systemów między tymi środowiskami może odbywać się wiele razy dziennie, należy robić to automatycznie. Dlatego ważne jest, aby opracować skrypty, które pozwolą łatwo wdrożyć budowaną aplikację w dowolnym środowisku.
Naturalną konsekwencją tego jest to, że powinny również istnieć skrypty, które pozwolą wdrożyć system na środowisko docelowe (produkcyjne) z podobną łatwością. Być może wdrażanie do produkcji nie odbywa się każdego dnia, ale automatyczne wdrażanie pomaga zarówno przyspieszyć proces, jak i zmniejszyć liczbę błędów. Jest to również tania opcja, ponieważ wykorzystuje te same rozwiązania, których używa się do wdrażania w środowiskach testowych.
Jeśli wdraża się do produkcji nowe wersje systemu, należy również rozważyć zautomatyzowane wycofywanie nowej wersji instalacji. Od czasu do czasu zdarzają się problemy z instalacjami i dobrze jest móc szybko wrócić do poprzedniej wersji wystemu. Możliwość automatycznego przywracania zmniejsza również wiele napięcia związanego z wdrażaniem, zachęcając ludzi do częstszego wdrażania, a tym samym do szybkiego udostępniania użytkownikom nowych funkcji.

Korzyści CI
Niewątpliwie jedną z największych korzyści płynących z prowadzenia CI do procesu wytwórczego oprogramowania jest zmniejszenie ryzyka związanego z budową systemu informatycznego.
Poniżej zostały przedstawione kolejne korzyści wypływające ze stosowania ciągłej integracji:
- błędy integracji są wykrywane bardzo szybko i są łatwe do wyśledzenia dzięki niewielkim zestawom zmian. Oszczędza to czas i pieniądze w całym okresie realizacji projektu.
- unika się zamieszania w końcowym etapie udostępnienia wersji finalnej oprogramowania, kiedy wprowadzane są niezbędne poprawki do kodu źródłowego.
- w przypadku błędów, jeśli programiści muszą przywrócić bazę kodu do stanu wolnego od błędów bez debugowania, wtedy tylko niewielka ilość zmian jest usuwana z repozytorium (ponieważ integracja występuje często)
- stała dostępność „aktualnej” kompilacji do celów testowania, demonstracji lub wydania
- częste sprawdzanie kodu zmusza programistów do tworzenia modularnego, mniej złożonego kodu
- szybsze udostępnianie kolejnych wersji oprogramowania dla klienta końcowego
Dzięki wprowadzeniu ciągłych testów automatycznych do CI korzyści mogą obejmować:
- wymuszanie dyscypliny tworzenia i uruchamiania częstych testów automatycznych
- natychmiastową informację zwrotna na temat wpływu zmian danego członka zespłu na cały system
- wskaźniki oprogramowania generowane na podstawie zautomatyzowanych testów i CI (takie jak wskaźniki pokrycia kodu, złożoność kodu i kompletność funkcji) koncentrują programistów na opracowywaniu funkcjonalnego kodu wysokiej jakości i pomagają rozwijać dynamikę i zaangażowanie w zespole programistów
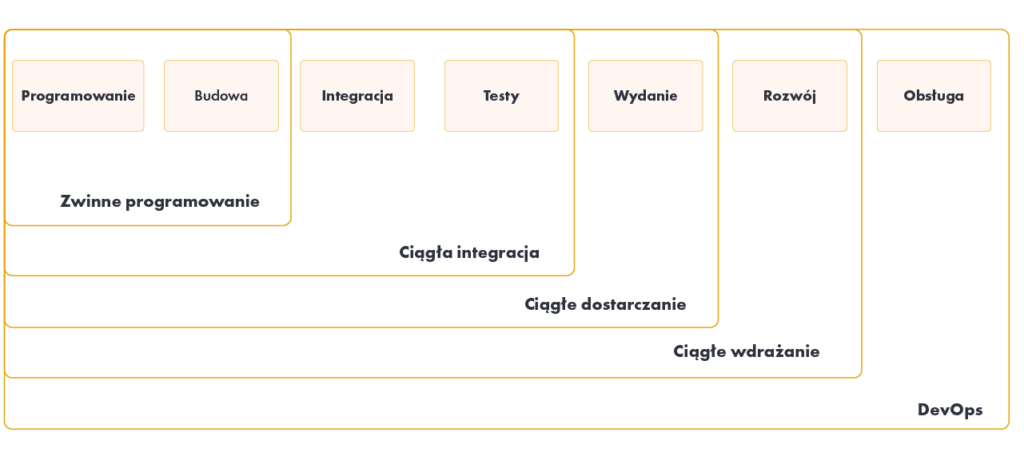
Continuous Integration / Continuous Delivery – różnice
Ciągła integracja zwykle odnosi się do integracji, budowania i testowania kodu w środowisku programistycznym. Na tym opiera się ciągłe dostarczanie (CD – ang. Continuous Delivery), zajmując się ostatnimi etapami wymaganymi do wdrożenia produkcyjnego.
Continuous Delivery opiera się na następujących zasadach:
- oprogramowanie można wdrażać przez cały cykl jego życia
- priorytetem zespołu jest utrzymanie oprogramowania w ciągłej możliwości jego wdrożenia
- każdy może uzyskać szybką, zautomatyzowaną informację zwrotną o gotowości produkcyjnej swoich systemów za każdym razem, gdy ktoś wprowadzi w nich zmiany
- na żądanie można wykonać automatyczne wdrożenie dowolnej wersji oprogramowania w dowolnym środowisku
Ciągłe dostarczanie jest czasami mylone z ciągłym wdrażaniem. Ciągłe wdrażanie oznacza, że każda zmiana przechodzi przez potok CI i automatycznie trafia do produkcji, co skutkuje wieloma wdrożeniami produkcyjnymi każdego dnia. Ciągłe dostarczanie oznacza po prostu, że jest możliwość wykonywania częstych wdrożeń, ale nie trzeba tego automatycznie, zwykle ze względu na firmy preferujące wolniejsze tempo wdrażania. Aby wykonać ciągłe wdrażanie, należy korzystać z ciągłego dostarczania.
Główne zalety ciągłego dostarczania to:
- zmniejszone ryzyko wdrożenia: ponieważ wdrażane są mniejsze zmiany, jest mniej błędów i łatwiej jest je naprawić, gdy pojawi się problem.
- wiarygodny postęp: wiele osób śledzi postępy, śledząc wykonaną pracę. Jeśli „gotowe” oznacza „programiści deklarują, że jest to zrobione”, jest to znacznie mniej wiarygodne, niż gdyby zostało wdrożone w środowisku produkcyjnym (lub podobnym do produkcji).
- opinie użytkowników: największym ryzykiem związanym z każdym wysiłkiem związanym z oprogramowaniem jest to, że w końcu zostanie stworzone coś, co nie jest przydatne końcowemu użytkownikowi. Im wcześniej i częściej użytkownik końcowy otrzymuje działające oprogramowanie, tym szybciej otrzymywana jest informacja zwrotna do zespołu realizującego oprogramowanie.
Continuous integration / Ciągła integracja – nieunikniona rzeczywistość
Idea ciągłej integracji staje się coraz bardziej powszechna jako jeden z głównych elementów procesu tworzenia oprogramowania i zarządzania projektami.
Wydaje się, że CI nie tylko pomaga integrować oprogramowanie ale równie w jakiś sposób integruje osoby, które to oprogramowanie współtworzą. Jak się okazuje CI ma duży wpływ na jakość oraz szybkość dostarczanego oprogramowania, co ma istotny wpływ na to w jaki sposób klienci końcowi odbierają to oprogramowanie oraz ich twórców.
Warto stosować ciągłą integrację oraz warto ulepszać ten proces każdego dnia – dla dobra i satysfakcji zespołów tworzących dzięki temu coraz to lepsze systemy informatyczne oraz dla powszechnego zadowolenia naszych klientów.